数据标注
数据标注
🏷️ 模块目标:掌握数据标注技术,构建高质量训练数据集
📖 数据标注概述
数据标注是机器学习和人工智能项目的基础工作,涉及为原始数据添加标签、注释或元数据,以便算法能够学习和识别模式。高质量的标注数据是模型性能的关键因素。
💡数据标注原理
数据标注是机器学习和人工智能领域中的一个关键步骤,它指的是给原始数据(如图像、文本、音频等)添加标签或注释,以便训练监督学习模型。标注的目的是让模型能够理解数据的含义,从而进行准确的预测和分类。在“无监督”或“自监督”语境下,“数据标注”不再依赖人工,而是让算法自己生成伪标签(pseudo label)。
未监督学习(Unsupervised Learning)
-
定义:未监督学习是一种机器学习方法,其中模型在训练过程中只使用未标注的数据,模型需要自己发现数据中的结构、模式或分布,而无需任何外部标签的指导。
-
特点:
- 无需标注数据:模型训练不依赖于人工标注,降低了数据准备的成本和时间。
- 发现隐藏模式:能够挖掘数据中潜在的结构和关系,例如通过聚类将相似的数据点分组。
- 评估困难: 缺乏ground-truth,需要间接指标(例如可视人工检查、下游任务效果)衡量
-
主要任务:
- 聚类:聚类是一种数据挖掘技术,它根据未标记数据的相似性或差异对其进行分组。聚类算法用于将原始的、未分类的数据对象处理成由信息中的结构或模式表示的组。
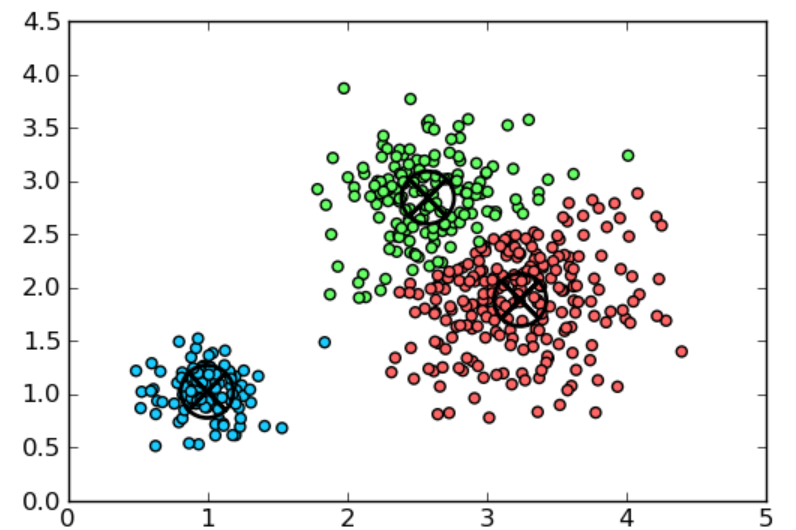
- 应用:
- 驾驶风格画像,为个性化自适应巡航(ACC)提供参数模板
- 轨迹模式挖掘,对百万条自然驾驶轨迹聚类,用于规划模块参考路径库
- 城市路网把 GPS 轨迹聚类,发现常发拥堵的“热点路段”
- 基因表达谱聚类,找出未知亚型癌症
-
关联规则:关联规则是一种基于规则的方法,用于查找给定数据集中的变量之间的关系。例如超市购物篮分析是关联规则在无监督学习中的经典应用,它自动从交易数据中发现商品之间的共买关系,无需任何标签或人工干预。
-

- 应用:
- 超市“啤酒→尿布”经典货架摆放
- 视频平台“看完《狂飙》→接着看《沉默的真相》”推荐
- 医院电子病历:出现“咳嗽+发热”常伴随“CT 白色磨玻璃影”,辅助诊断
- 银行反洗钱:同一 IP 短时间内“多笔小额转入→立刻大额转出”触发告警
-
降维:虽然更多数据通常会产生更准确的结果,但它也会影响机器学习算法的性能(例如过拟合),还可能使数据集难以可视化。当给定的数据集中的特征或维度数量过高时,可以使用降维技术。它将数据输入的数量减少到合适的大小,同时尽可能地保持数据集的完整性。例如,AutoEncoder降维
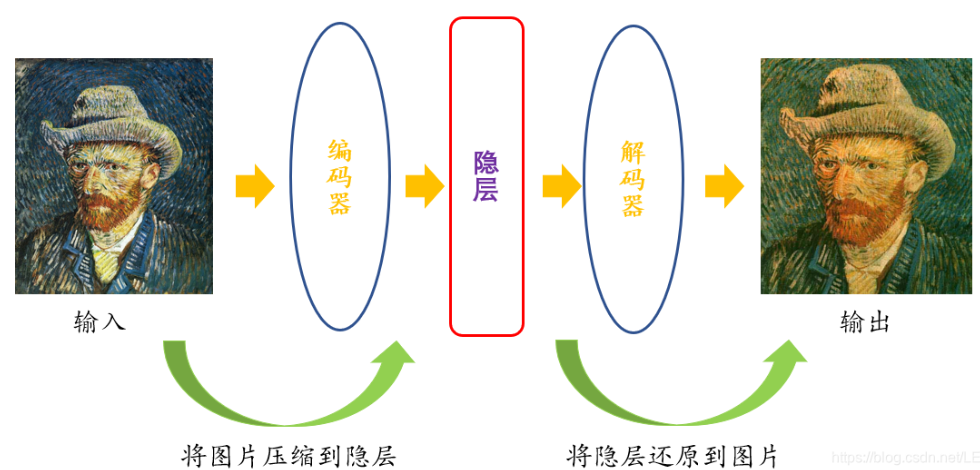
- 应用:
- 人脸识别先把 512-D 特征降到 2-D,可视化查看不同族群分布
- 工业质检高光谱图像 200 个波段→3 个主成分,压缩 98 % 存储
- 文本舆情把 10 万词袋维数降到 50-D LDA 主题,快速检索
- 金融风控 1000+ 变量→10 维因子,喂给逻辑回归防止过拟合
-
异常检测:在只有“正常”样本(或极少量异常)的前提下,让算法自己学会“什么是正常”,从而把偏离正常分布的观测判为异常。
-
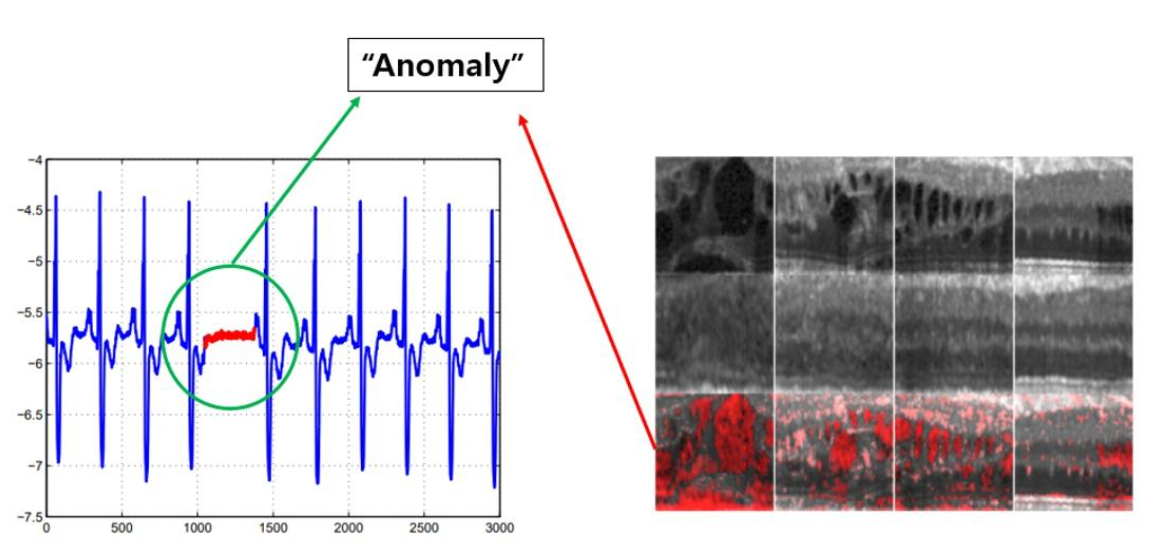
- 应用:
- 边缘场景发现,在大规模驾驶数据中找出边缘场景
- 信评系统实时检测“盗刷”交易,30 秒内阻断
- 能源公司发现输电线路瞬时电流突增,定位短路隐患
- 医学影像 AI 把“罕见结节”自动圈出,供放射科医生重点复核
自监督学习(Self-Supervised Learning)
-
定义:自监督学习主要是利用辅助任务(pretext)从大规模的无监督数据中挖掘自身的监督信息,通过这种构造的监督信息对网络进行训练,从而学习到对下游任务有价值的表征。
- 特点:
- 无需人工标签:利用数据内在结构自动生成“伪标签”,数据准备成本接近无监督。
- 表征质量高:预训练目标与下游任务共享语义信息,通常比传统无监督特征更具判别力。
- 迁移性强:同一套自监督预训练权重可微调于分类、检测、分割等多种任务,显著提升小样本场景性能。
- 评估间接:需依赖下游任务精度或线性探测精度作为代理指标,缺乏统一 ground-truth 衡量表征优劣。
-
主要任务:
-
基于上下文的自监督学习:基于数据本身的上下文信息,我们其实可以构造很多任务,比如在 NLP 领域中最重要的算法 Word2vec 。Word2vec 主要是利用语句的顺序,例如 CBOW 通过前后的词来预测中间的词,而 Skip-Gram 通过中间的词来预测前后的词。
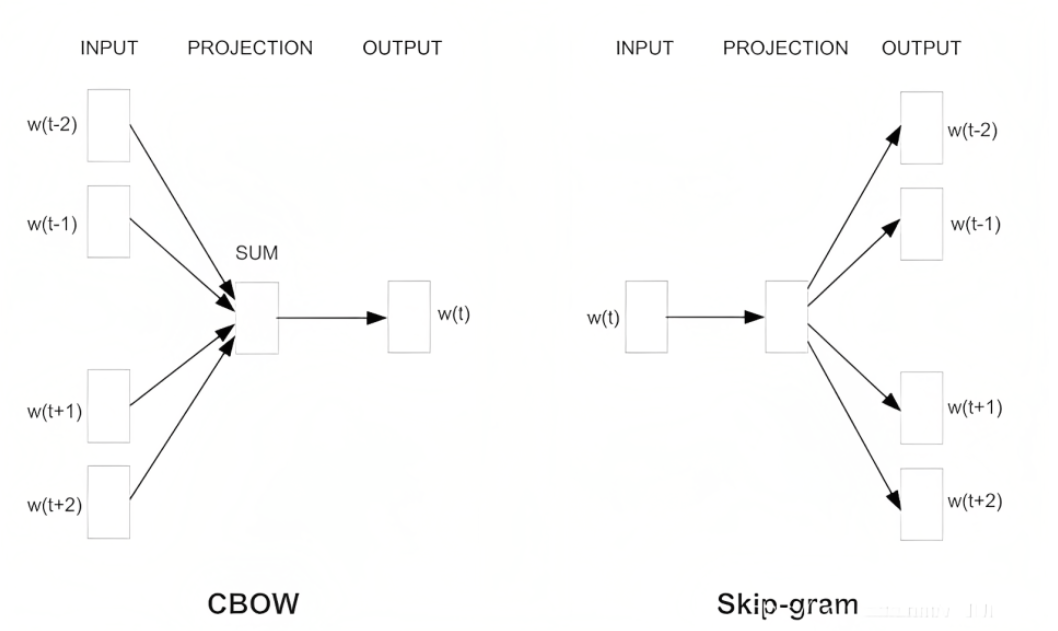
而在图像中,可以通过一种名为 Jigsaw(拼图)的方式来构造辅助任务。我们可以将一张图分成 9 个部分,然后通过预测这几个部分的相对位置来产生损失。比如我们输入这张图中的小猫的眼睛和右耳朵,期待让模型学习到猫的右耳朵是在脸部的右上方的,如果模型能很好的完成这个任务,那么我们就可以认为模型学习到的表征是具有语义信息的。
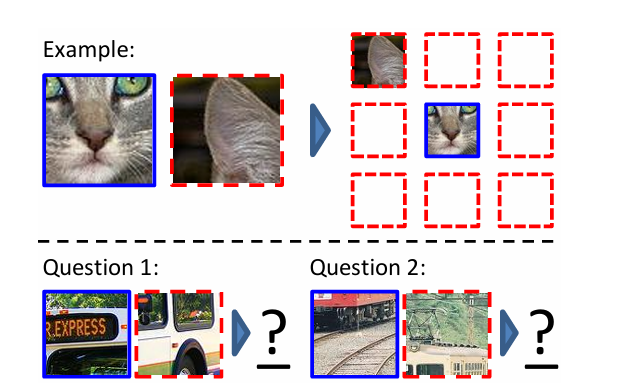
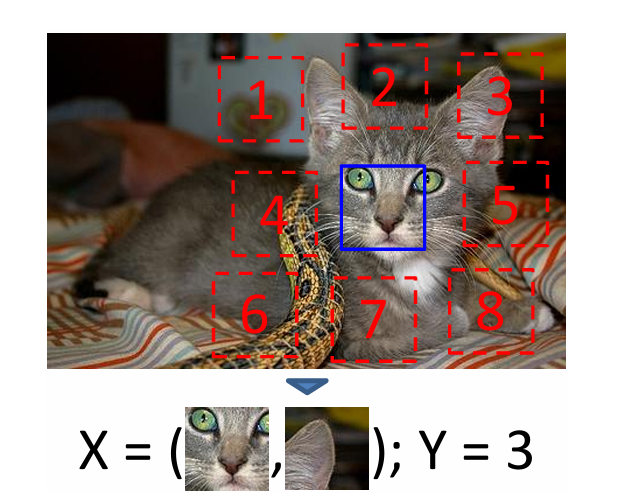
-
基于时序的自监督学习:最能体现时序的数据类型就是视频了,第一种思想是基于帧的相似性,对于视频中的每一帧,简单来说我们可以认为视频中的相邻帧特征是相似的,而相隔较远的视频帧是不相似的,通过构建这种相似(position)和不相似(negative)的样本来进行自监督约束。
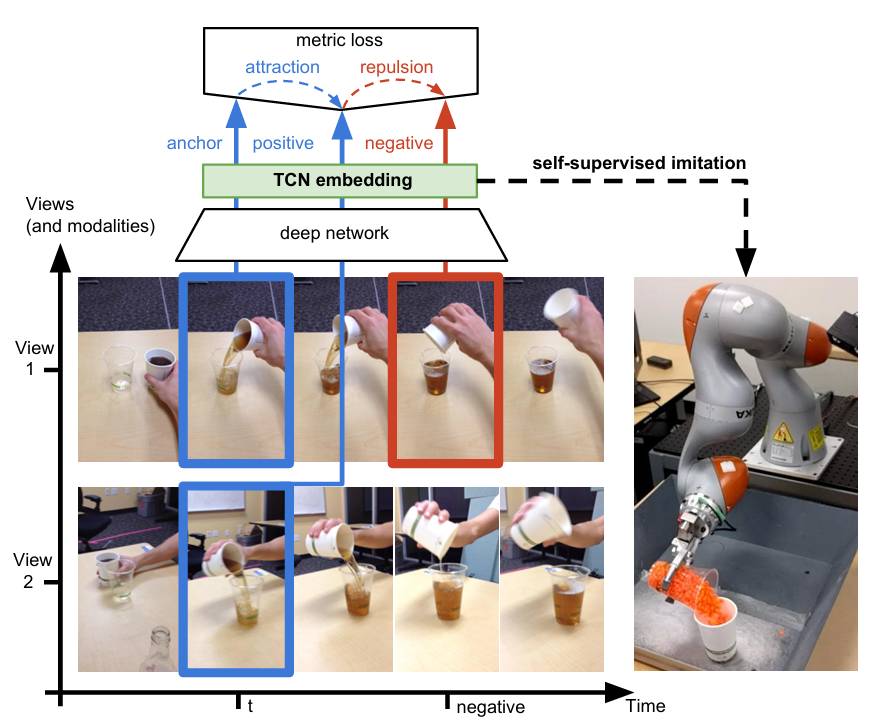
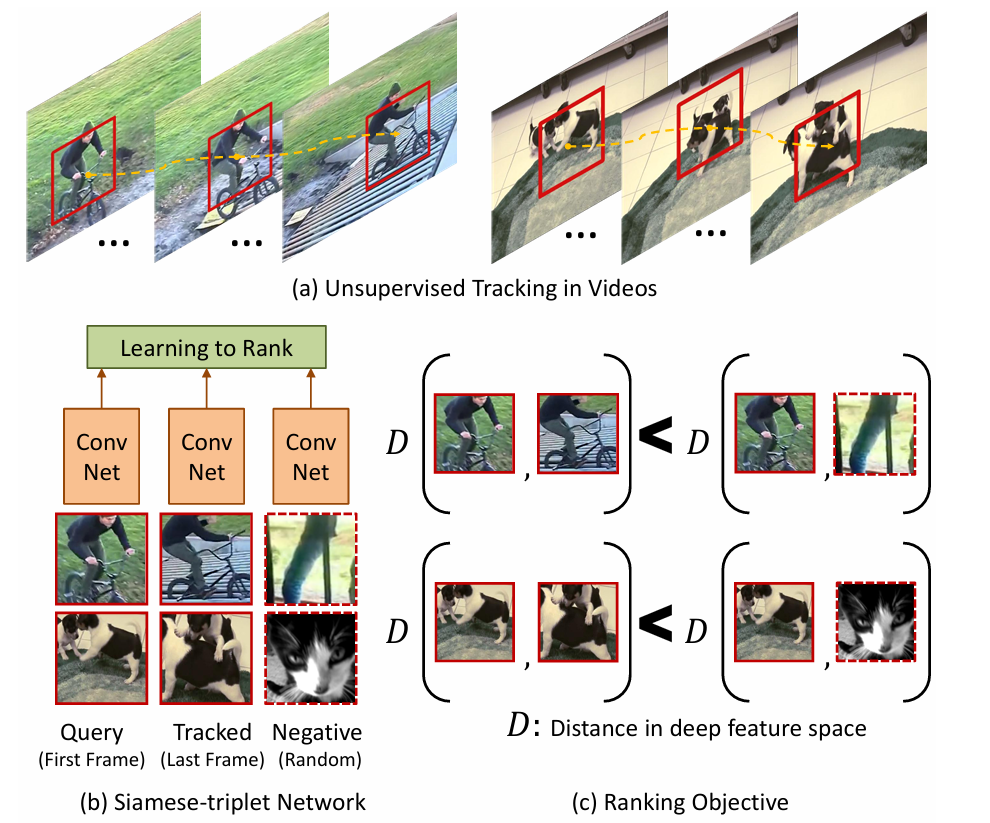
在大量的无标签视频中进行无监督追踪,获取大量的物体追踪框。那么对于一个物体追踪框在不同帧的特征应该是相似的(positive),而对于不同物体的追踪框中的特征应该是不相似的(negative)。
视频的先后顺序也是一种自监督信息。比如ECCV 2016, Misra, I. [19] 等人提出基于顺序约束的方法,可以从视频中采样出正确的视频序列和不正确的视频序列,构造成正负样本对然后进行训练。简而言之,就是设计一个模型,来判断当前的视频序列是否是正确的顺序。

-
基于对比的自监督学习:通过学习对两个事物的相似或不相似进行编码来构建表征。对比学习中,通过在输入样本之间进行比较来学习表示。对比学习不是一次从单个数据样本中学习信号,而是通过在不同样本之间进行比较来学习。对比学习通过同时最大化同一图像的不同变换视图(例如剪裁,翻转,颜色变换等)之间的一致性,以及最小化不同图像的变换视图之间的一致性来学习的。 简单来说,就是对比学习要做到相同的图像经过各类变换之后,依然能识别出是同一张图像,所以要最大化各类变换后图像的相似度(因为都是同一个图像得到的)。

-
-
应用:
- 计算机视觉:通过预测图像块的相对位置或旋转角度,训练模型学习图像的语义特征。
- 自然语言处理:采用掩码语言模型(如 BERT),预测句子中被掩盖的词语,理解词汇和语法结构。
🎯 标注类型与应用
图像标注
-
分类标注:为图像分配类别标签

-
目标检测:标注物体边界框和类别

-
语义分割:像素级别的类别标注

-
实例分割:区分同类别的不同实例
-
关键点检测:标注人体姿态、面部特征点
文本标注
-
情感分析:标注文本情感倾向
-
命名实体识别:标注人名、地名、机构名
-
关系抽取:标注实体间的关系
-
文本分类:为文档分配主题标签
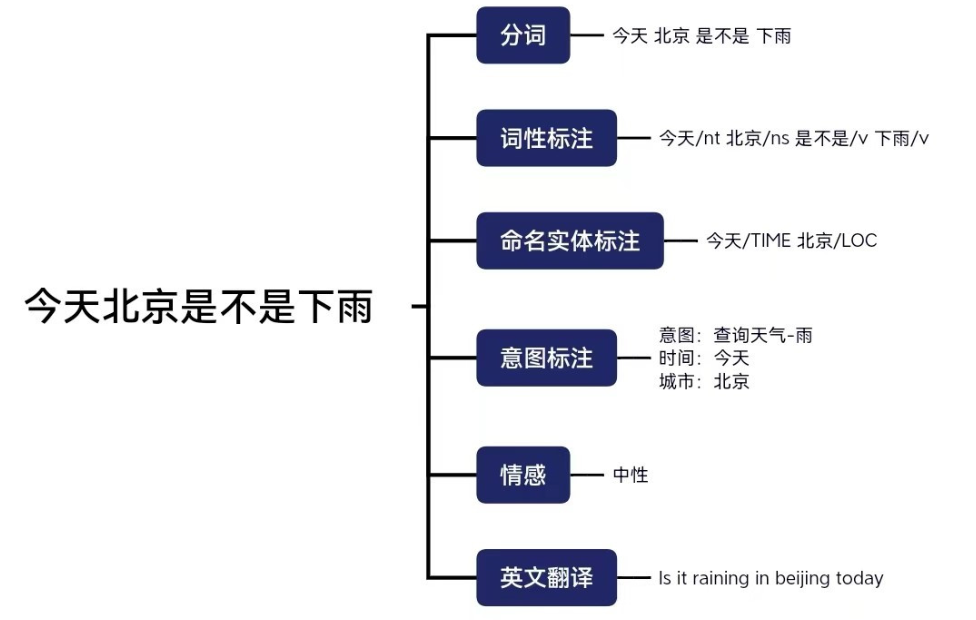
-
机器翻译:提供翻译对照
音频标注
- 语音识别:标注语音内容
- 音乐分类:标注音乐风格、情绪
- 环境声音:标注声音事件和场景
- 说话人识别:标注说话人身份
视频标注
-
动作识别:标注视频中的行为动作
-
场景分割:标注视频场景边界
-
目标跟踪:标注目标在视频中的轨迹
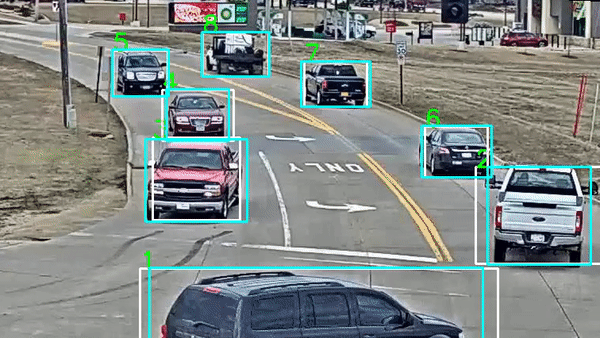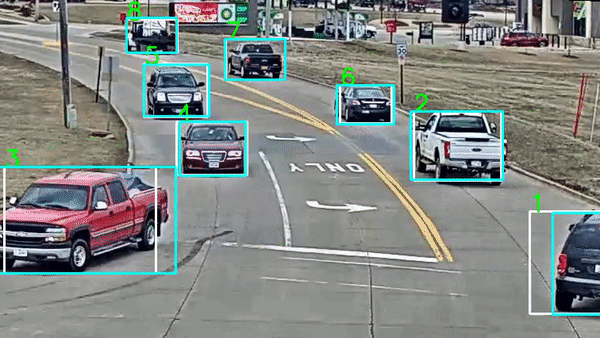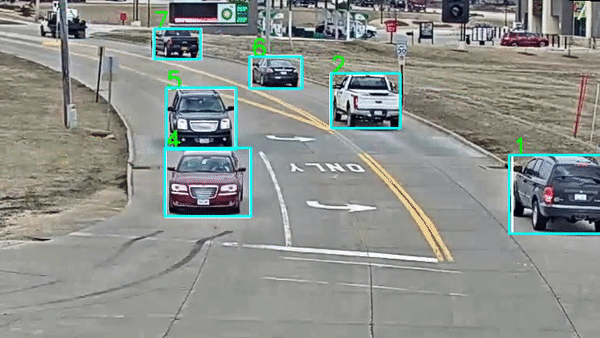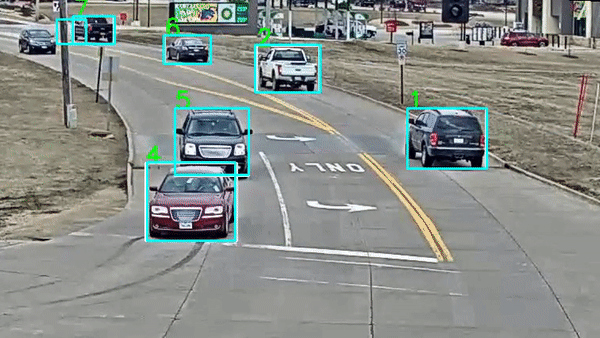
-
事件检测:标注特定事件的时间点
场景流标注
描述图像或视频中每个像素在三维空间中的运动矢量,包含深度信息和运动轨迹。

占用地图标注
将环境划分为网格单元,标注每个单元是否被物体占据。

场景说明标注
用自然语言描述图像或视频的内容,提供高层次的语义信息。
“在阳光明媚的公园里,孩子们正在放风筝,背景有长椅和树木。”
🔥常用的数据标注方法
为了提高标注效率和质量,研究者开发了多种数据标注方法,结合人工智能和机器学习技术,减少人工参与。
1. 跨域学习生成伪标签(Cross-Domain Pseudo-Labeling)
- 定义:利用来自不同领域但相关的已标注数据,训练模型在当前领域的未标注数据上生成伪标签。
- 步骤:
- 源域训练:在源域(已标注的相关领域)上训练一个性能良好的模型。
- 目标域预测:使用该模型对目标域(未标注的数据)进行预测,生成伪标签。
- 伪标签优化:通过迭代自训练或协同训练,逐步修正伪标签的错误,提高准确性。
- 应用场景:
- 领域适应:当目标领域缺乏标注数据时,利用源领域的知识进行迁移。
- 数据增强:扩充目标领域的标注数据,提升模型性能。
- 示例:
- 利用已标注的白天驾驶图像训练模型,生成夜间驾驶图像的伪标签。
2. 离线目标追踪(Offline Object Tracking)
- 定义:在离线情况下,对视频序列中的目标进行追踪和标注,获取其运动轨迹。
- 流程:
- 检测阶段:在每帧中检测目标物体的位置。
- 关联阶段:根据目标的特征(如外观、运动)将不同帧中的检测结果关联起来。
- 轨迹生成:为每个目标生成完整的运动轨迹,分配唯一 ID。
- 优势:
- 高精度:利用全局信息,对目标进行更准确的关联。
- 纠错能力:可以通过后处理步骤,修正追踪过程中的错误。
- 应用场景:
- 视频分析:分析监控录像中人员或车辆的行为。
- 数据标注:为视频数据生成目标追踪的标注,用于训练追踪模型。
- 示例:
- 标注一段交通视频中所有车辆的轨迹,用于训练自动驾驶系统。
3. 离线场景流估计(Offline Scene Flow Estimation)
- 定义:从预先采集的图像或视频序列中,计算每个像素的三维运动矢量。
- 方法:
- 立体视觉:利用双目相机获取的深度信息,结合光流法计算场景流。
- 深度学习:训练神经网络,从图像对中直接预测场景流。
- 应用:
- 三维重建:构建动态场景的三维模型。
- 运动分析:分析场景中物体的运动模式。
- 示例:
- 估计行人过马路时的运动矢量,预测其未来位置。
4. 场景分类(Scene Classification)
- 定义:根据图像或视频的内容,将其归类到预定义的场景类别中。
- 方法:
- 基于特征:提取图像的纹理、颜色、形状等特征,使用分类器(如 SVM、随机森林)进行分类。
- 基于深度学习:使用卷积神经网络(CNN)等模型,自动学习图像的特征,进行分类。
- 应用场景:
- 图像管理:对大量图像进行自动分类,方便检索和管理。
- 智能推荐:根据用户上传的图片,推荐相关的标签或内容。
5. 主动学习(Active Learning)
- 定义:通过智能选择最有价值的样本进行人工标注,以最小的标注量获得最大的模型性能提升。
- 流程:
- 初始训练:使用少量已标注数据训练模型。
- 样本选择:模型从大量未标注数据中,选择不确定性高或信息量大的样本。
- 人工标注:专家对选中的样本进行标注。
- 模型更新:将新标注的数据加入训练集,重新训练模型。
- 优势:
- 高效性:减少冗余标注,降低标注成本。
- 适应性:模型性能随着标注数据的增加而快速提升。
- 应用场景:
- 医疗图像:筛选出需要专家诊断的疑难病例。
- 文本分类:挑选出对模型最有帮助的文本进行标注。
6. 众包标注(Crowdsourcing)
- 定义:将标注任务分发给大量非专业的标注者(众包工人),通过汇聚众人的力量完成标注。
- 平台:
- Amazon Mechanical Turk:一个流行的众包平台,可以发布微任务。
- 国内平台:如“数据堂”、“百度众测”。
- 质量控制:
- 多重标注:同一数据由多个标注者标注,通过投票或一致性检查确保质量。
- 测试题:插入已知答案的测试题,评估标注者的可靠性。
- 适用性:
- 简单任务:如图像分类、边界框标注。
- 成本敏感:在预算有限的情况下,获取大量标注数据。
- 示例:
- 收集公众对社交媒体帖子的情感标注,用于情感分析模型。
7. 合成数据生成(Synthetic Data Generation)
- 定义:利用计算机模拟或算法生成带有标注的合成数据,用于训练模型。
- 方法:
- 图形渲染:使用 3D 建模和渲染技术,生成逼真的图像和视频。
- 生成对抗网络(GAN):训练生成模型,产生与真实数据相似的合成数据。
- 优势:
- 无限数据:可以生成任意数量的标注数据。
- 多样性:控制数据的分布和特征,覆盖更多场景。
- 挑战:
- 真实感:合成数据需要与真实数据足够相似,否则可能导致模型性能下降。
- 领域差距:合成数据与真实数据之间可能存在分布差异。
- 应用场景:
- 自动驾驶:生成各种交通场景,训练感知模型。
- 机器人抓取:模拟物体和机械臂的交互,生成训练数据。
- 示例:
- 使用游戏引擎生成不同天气和光照条件下的道路场景,用于训练车辆检测模型。
🛠️ 标注工具与平台
开源标注工具
图像标注工具
# LabelImg - 目标检测标注
# 安装:pip install labelImg
# 使用:labelImg
# 基于Python的自定义标注工具
import tkinter as tk
from tkinter import filedialog, messagebox
from PIL import Image, ImageTk
import json
import os
class ImageAnnotationTool:
def __init__(self, root):
self.root = root
self.root.title("图像标注工具")
self.root.geometry("1200x800")
self.image_path = ""
self.annotations = []
self.current_bbox = None
self.start_x = 0
self.start_y = 0
self.setup_ui()
def setup_ui(self):
# 菜单栏
menubar = tk.Menu(self.root)
self.root.config(menu=menubar)
file_menu = tk.Menu(menubar, tearoff=0)
menubar.add_cascade(label="文件", menu=file_menu)
file_menu.add_command(label="打开图像", command=self.load_image)
file_menu.add_command(label="保存标注", command=self.save_annotations)
file_menu.add_command(label="加载标注", command=self.load_annotations)
# 主框架
main_frame = tk.Frame(self.root)
main_frame.pack(fill=tk.BOTH, expand=True, padx=10, pady=10)
# 左侧:图像显示
self.image_frame = tk.Frame(main_frame, bg="white")
self.image_frame.pack(side=tk.LEFT, fill=tk.BOTH, expand=True)
self.canvas = tk.Canvas(self.image_frame, bg="white")
self.canvas.pack(fill=tk.BOTH, expand=True)
# 绑定鼠标事件
self.canvas.bind("<Button-1>", self.start_bbox)
self.canvas.bind("<B1-Motion>", self.draw_bbox)
self.canvas.bind("<ButtonRelease-1>", self.end_bbox)
# 右侧:控制面板
control_frame = tk.Frame(main_frame, width=300)
control_frame.pack(side=tk.RIGHT, fill=tk.Y, padx=(10, 0))
control_frame.pack_propagate(False)
# 类别选择
tk.Label(control_frame, text="选择类别:", font=("Arial", 12)).pack(pady=5)
self.class_var = tk.StringVar(value="person")
self.class_entry = tk.Entry(control_frame, textvariable=self.class_var)
self.class_entry.pack(pady=5, fill=tk.X)
# 预定义类别
classes = ["person", "car", "bike", "dog", "cat"]
for cls in classes:
btn = tk.Button(control_frame, text=cls,
command=lambda c=cls: self.class_var.set(c))
btn.pack(pady=2, fill=tk.X)
# 标注列表
tk.Label(control_frame, text="标注列表:", font=("Arial", 12)).pack(pady=(20, 5))
self.annotation_listbox = tk.Listbox(control_frame, height=10)
self.annotation_listbox.pack(fill=tk.BOTH, expand=True, pady=5)
# 删除按钮
tk.Button(control_frame, text="删除选中标注",
command=self.delete_annotation).pack(pady=5, fill=tk.X)
# 清空按钮
tk.Button(control_frame, text="清空所有标注",
command=self.clear_annotations).pack(pady=5, fill=tk.X)
def load_image(self):
file_path = filedialog.askopenfilename(
filetypes=[("Image files", "*.jpg *.jpeg *.png *.bmp *.gif")]
)
if file_path:
self.image_path = file_path
self.display_image()
def display_image(self):
if self.image_path:
image = Image.open(self.image_path)
# 调整图像大小以适应画布
canvas_width = self.canvas.winfo_width()
canvas_height = self.canvas.winfo_height()
if canvas_width > 1 and canvas_height > 1:
image.thumbnail((canvas_width, canvas_height), Image.Resampling.LANCZOS)
self.photo = ImageTk.PhotoImage(image)
self.canvas.delete("all")
self.canvas.create_image(0, 0, anchor=tk.NW, image=self.photo)
self.canvas.config(scrollregion=self.canvas.bbox("all"))
def start_bbox(self, event):
self.start_x = self.canvas.canvasx(event.x)
self.start_y = self.canvas.canvasy(event.y)
if self.current_bbox:
self.canvas.delete(self.current_bbox)
self.current_bbox = self.canvas.create_rectangle(
self.start_x, self.start_y, self.start_x, self.start_y,
outline="red", width=2
)
def draw_bbox(self, event):
cur_x = self.canvas.canvasx(event.x)
cur_y = self.canvas.canvasy(event.y)
self.canvas.coords(self.current_bbox, self.start_x, self.start_y, cur_x, cur_y)
def end_bbox(self, event):
end_x = self.canvas.canvasx(event.x)
end_y = self.canvas.canvasy(event.y)
# 确保边界框有效
if abs(end_x - self.start_x) > 5 and abs(end_y - self.start_y) > 5:
annotation = {
"class": self.class_var.get(),
"bbox": [
min(self.start_x, end_x),
min(self.start_y, end_y),
max(self.start_x, end_x),
max(self.start_y, end_y)
]
}
self.annotations.append(annotation)
self.update_annotation_list()
else:
self.canvas.delete(self.current_bbox)
self.current_bbox = None
def update_annotation_list(self):
self.annotation_listbox.delete(0, tk.END)
for i, ann in enumerate(self.annotations):
self.annotation_listbox.insert(tk.END,
f"{i+1}. {ann['class']}: {ann['bbox']}")
def delete_annotation(self):
selection = self.annotation_listbox.curselection()
if selection:
index = selection[0]
del self.annotations[index]
self.update_annotation_list()
self.redraw_annotations()
def clear_annotations(self):
self.annotations = []
self.update_annotation_list()
self.canvas.delete("bbox")
def redraw_annotations(self):
self.canvas.delete("bbox")
for ann in self.annotations:
bbox = ann["bbox"]
self.canvas.create_rectangle(
bbox[0], bbox[1], bbox[2], bbox[3],
outline="red", width=2, tags="bbox"
)
def save_annotations(self):
if not self.image_path:
messagebox.showwarning("警告", "请先加载图像")
return
annotation_file = self.image_path.rsplit('.', 1)[0] + '.json'
annotation_data = {
"image_path": self.image_path,
"annotations": self.annotations
}
with open(annotation_file, 'w', encoding='utf-8') as f:
json.dump(annotation_data, f, indent=2, ensure_ascii=False)
messagebox.showinfo("成功", f"标注已保存至 {annotation_file}")
def load_annotations(self):
if not self.image_path:
messagebox.showwarning("警告", "请先加载图像")
return
annotation_file = self.image_path.rsplit('.', 1)[0] + '.json'
if os.path.exists(annotation_file):
with open(annotation_file, 'r', encoding='utf-8') as f:
data = json.load(f)
self.annotations = data.get("annotations", [])
self.update_annotation_list()
self.redraw_annotations()
else:
messagebox.showinfo("信息", "未找到对应的标注文件")
# 启动标注工具
if __name__ == "__main__":
root = tk.Tk()
app = ImageAnnotationTool(root)
root.mainloop()
文本标注工具
import streamlit as st
import pandas as pd
import json
from datetime import datetime
class TextAnnotationTool:
def __init__(self):
self.init_session_state()
def init_session_state(self):
if 'texts' not in st.session_state:
st.session_state.texts = []
if 'annotations' not in st.session_state:
st.session_state.annotations = {}
if 'current_index' not in st.session_state:
st.session_state.current_index = 0
def load_texts(self, file):
"""加载待标注文本"""
if file.type == "text/csv":
df = pd.read_csv(file)
if 'text' in df.columns:
st.session_state.texts = df['text'].tolist()
else:
st.error("CSV文件必须包含'text'列")
elif file.type == "application/json":
data = json.load(file)
if isinstance(data, list):
st.session_state.texts = data
else:
st.error("JSON文件必须是文本列表")
else:
# 纯文本文件
content = str(file.read(), "utf-8")
st.session_state.texts = content.split('\n')
st.session_state.current_index = 0
st.success(f"成功加载 {len(st.session_state.texts)} 条文本")
def annotate_sentiment(self):
"""情感分析标注"""
if not st.session_state.texts:
st.warning("请先上传文本文件")
return
st.subheader("情感分析标注")
# 显示当前文本
current_text = st.session_state.texts[st.session_state.current_index]
st.text_area("当前文本", current_text, height=100, disabled=True)
# 标注选项
sentiment = st.radio(
"选择情感标签",
["积极", "消极", "中性"],
key=f"sentiment_{st.session_state.current_index}"
)
# 置信度
confidence = st.slider("标注置信度", 0.0, 1.0, 0.8, 0.1)
# 保存标注
if st.button("保存标注"):
text_id = st.session_state.current_index
st.session_state.annotations[text_id] = {
"text": current_text,
"sentiment": sentiment,
"confidence": confidence,
"timestamp": datetime.now().isoformat()
}
st.success("标注已保存")
# 自动跳转到下一条
if st.session_state.current_index < len(st.session_state.texts) - 1:
st.session_state.current_index += 1
st.experimental_rerun()
def annotate_ner(self):
"""命名实体识别标注"""
if not st.session_state.texts:
st.warning("请先上传文本文件")
return
st.subheader("命名实体识别标注")
current_text = st.session_state.texts[st.session_state.current_index]
st.text_area("当前文本", current_text, height=100, disabled=True)
# 实体类型
entity_types = ["PERSON", "ORG", "GPE", "MONEY", "DATE", "TIME"]
# 实体标注
entities = []
st.write("标注实体:")
for i in range(5): # 最多标注5个实体
col1, col2, col3, col4 = st.columns([2, 2, 1, 1])
with col1:
entity_text = st.text_input(f"实体文本 {i+1}", key=f"entity_text_{i}")
with col2:
entity_type = st.selectbox(f"实体类型 {i+1}",
[""] + entity_types, key=f"entity_type_{i}")
with col3:
start_pos = st.number_input(f"开始位置 {i+1}",
min_value=0, key=f"start_{i}")
with col4:
end_pos = st.number_input(f"结束位置 {i+1}",
min_value=0, key=f"end_{i}")
if entity_text and entity_type:
entities.append({
"text": entity_text,
"type": entity_type,
"start": int(start_pos),
"end": int(end_pos)
})
# 保存标注
if st.button("保存NER标注"):
text_id = st.session_state.current_index
st.session_state.annotations[text_id] = {
"text": current_text,
"entities": entities,
"timestamp": datetime.now().isoformat()
}
st.success("NER标注已保存")
def navigation(self):
"""导航控制"""
if st.session_state.texts:
col1, col2, col3 = st.columns([1, 2, 1])
with col1:
if st.button("上一条"):
if st.session_state.current_index > 0:
st.session_state.current_index -= 1
st.experimental_rerun()
with col2:
st.write(f"当前进度: {st.session_state.current_index + 1} / {len(st.session_state.texts)}")
with col3:
if st.button("下一条"):
if st.session_state.current_index < len(st.session_state.texts) - 1:
st.session_state.current_index += 1
st.experimental_rerun()
def export_annotations(self):
"""导出标注结果"""
if st.session_state.annotations:
annotations_json = json.dumps(st.session_state.annotations,
indent=2, ensure_ascii=False)
st.download_button(
label="下载标注结果",
data=annotations_json,
file_name=f"annotations_{datetime.now().strftime('%Y%m%d_%H%M%S')}.json",
mime="application/json"
)
def run(self):
"""运行主程序"""
st.title("文本标注工具")
# 文件上传
uploaded_file = st.file_uploader(
"上传文本文件",
type=['txt', 'csv', 'json'],
help="支持txt、csv、json格式"
)
if uploaded_file:
self.load_texts(uploaded_file)
# 标注类型选择
annotation_type = st.sidebar.selectbox(
"选择标注类型",
["情感分析", "命名实体识别"]
)
# 导航
self.navigation()
# 标注界面
if annotation_type == "情感分析":
self.annotate_sentiment()
elif annotation_type == "命名实体识别":
self.annotate_ner()
# 导出功能
st.sidebar.subheader("导出标注")
self.export_annotations()
# 显示标注统计
if st.session_state.annotations:
st.sidebar.subheader("标注统计")
st.sidebar.write(f"已标注: {len(st.session_state.annotations)} 条")
st.sidebar.write(f"剩余: {len(st.session_state.texts) - len(st.session_state.annotations)} 条")
# 启动应用
if __name__ == "__main__":
app = TextAnnotationTool()
app.run()
商业标注平台
众包标注平台
- Amazon Mechanical Turk:亚马逊众包平台
- Figure Eight (now Appen):专业数据标注服务
- Labelbox:端到端标注平台
- Scale AI:AI训练数据平台
企业级标注解决方案
- Supervisely:计算机视觉标注平台
- Hasty.ai:AI辅助标注工具
- V7 Labs:医学图像标注专用
- Dataloop:数据管理和标注平台
📊 标注质量控制
质量评估指标
import numpy as np
from sklearn.metrics import cohen_kappa_score, accuracy_score
import pandas as pd
class AnnotationQualityControl:
def __init__(self):
pass
def inter_annotator_agreement(self, annotations_df):
"""计算标注者间一致性"""
annotators = annotations_df['annotator'].unique()
agreements = {}
for i, ann1 in enumerate(annotators):
for ann2 in annotators[i+1:]:
# 获取两个标注者的共同标注
ann1_data = annotations_df[annotations_df['annotator'] == ann1]
ann2_data = annotations_df[annotations_df['annotator'] == ann2]
# 合并共同项目
common = pd.merge(ann1_data, ann2_data, on='item_id',
suffixes=('_1', '_2'))
if len(common) > 0:
# 计算Cohen's Kappa
kappa = cohen_kappa_score(common['label_1'], common['label_2'])
accuracy = accuracy_score(common['label_1'], common['label_2'])
agreements[f"{ann1}_vs_{ann2}"] = {
'kappa': kappa,
'accuracy': accuracy,
'common_items': len(common)
}
return agreements
def calculate_annotation_time_stats(self, annotations_df):
"""计算标注时间统计"""
if 'start_time' in annotations_df.columns and 'end_time' in annotations_df.columns:
annotations_df['duration'] = (
pd.to_datetime(annotations_df['end_time']) -
pd.to_datetime(annotations_df['start_time'])
).dt.total_seconds()
stats = {
'mean_duration': annotations_df['duration'].mean(),
'median_duration': annotations_df['duration'].median(),
'std_duration': annotations_df['duration'].std(),
'min_duration': annotations_df['duration'].min(),
'max_duration': annotations_df['duration'].max()
}
# 检测异常快速或缓慢的标注
Q1 = annotations_df['duration'].quantile(0.25)
Q3 = annotations_df['duration'].quantile(0.75)
IQR = Q3 - Q1
outliers = annotations_df[
(annotations_df['duration'] < Q1 - 1.5 * IQR) |
(annotations_df['duration'] > Q3 + 1.5 * IQR)
]
stats['outlier_count'] = len(outliers)
stats['outlier_percentage'] = len(outliers) / len(annotations_df) * 100
return stats
else:
return {"error": "缺少时间戳信息"}
def detect_annotation_patterns(self, annotations_df):
"""检测标注模式异常"""
patterns = {}
# 检测标注分布
label_distribution = annotations_df['label'].value_counts(normalize=True)
patterns['label_distribution'] = label_distribution.to_dict()
# 检测标注者偏好
annotator_patterns = annotations_df.groupby('annotator')['label'].value_counts(normalize=True)
patterns['annotator_preferences'] = annotator_patterns.to_dict()
# 检测时间偏好
if 'timestamp' in annotations_df.columns:
annotations_df['hour'] = pd.to_datetime(annotations_df['timestamp']).dt.hour
time_patterns = annotations_df.groupby('annotator')['hour'].apply(
lambda x: x.value_counts(normalize=True).head(3)
)
patterns['time_preferences'] = time_patterns.to_dict()
return patterns
# 使用示例
annotations_data = pd.DataFrame({
'item_id': range(100),
'annotator': np.random.choice(['A', 'B', 'C'], 100),
'label': np.random.choice(['positive', 'negative', 'neutral'], 100),
'confidence': np.random.uniform(0.5, 1.0, 100),
'start_time': pd.date_range('2024-01-01', periods=100, freq='H'),
'end_time': pd.date_range('2024-01-01 00:30:00', periods=100, freq='H')
})
qc = AnnotationQualityControl()
agreements = qc.inter_annotator_agreement(annotations_data)
time_stats = qc.calculate_annotation_time_stats(annotations_data)
patterns = qc.detect_annotation_patterns(annotations_data)
print("标注者间一致性:", agreements)
print("标注时间统计:", time_stats)
print("标注模式:", patterns)
主动学习与自动化标注
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics import accuracy_score
import numpy as np
class ActiveLearningAnnotation:
def __init__(self, model=None):
self.model = model or RandomForestClassifier(n_estimators=100)
self.vectorizer = TfidfVectorizer(max_features=1000)
self.labeled_data = []
self.unlabeled_data = []
def add_labeled_data(self, texts, labels):
"""添加已标注数据"""
for text, label in zip(texts, labels):
self.labeled_data.append({'text': text, 'label': label})
def add_unlabeled_data(self, texts):
"""添加未标注数据"""
for text in texts:
self.unlabeled_data.append({'text': text})
def train_model(self):
"""训练当前模型"""
if len(self.labeled_data) < 2:
return False
texts = [item['text'] for item in self.labeled_data]
labels = [item['label'] for item in self.labeled_data]
# 特征提取
X = self.vectorizer.fit_transform(texts)
# 训练模型
self.model.fit(X, labels)
return True
def uncertainty_sampling(self, n_samples=10):
"""不确定性采样"""
if not self.unlabeled_data:
return []
texts = [item['text'] for item in self.unlabeled_data]
X = self.vectorizer.transform(texts)
# 获取预测概率
probabilities = self.model.predict_proba(X)
# 计算不确定性(熵)
uncertainties = []
for prob in probabilities:
entropy = -np.sum(prob * np.log(prob + 1e-10))
uncertainties.append(entropy)
# 选择最不确定的样本
uncertain_indices = np.argsort(uncertainties)[-n_samples:]
selected_samples = []
for idx in uncertain_indices:
selected_samples.append({
'index': idx,
'text': self.unlabeled_data[idx]['text'],
'uncertainty': uncertainties[idx],
'probabilities': probabilities[idx].tolist()
})
return selected_samples
def diversity_sampling(self, n_samples=10):
"""多样性采样"""
if not self.unlabeled_data:
return []
texts = [item['text'] for item in self.unlabeled_data]
X = self.vectorizer.transform(texts).toarray()
# 选择多样性最大的样本
selected_indices = []
remaining_indices = list(range(len(texts)))
# 随机选择第一个样本
first_idx = np.random.choice(remaining_indices)
selected_indices.append(first_idx)
remaining_indices.remove(first_idx)
# 迭代选择与已选样本差异最大的样本
for _ in range(min(n_samples - 1, len(remaining_indices))):
max_min_distance = -1
best_idx = None
for candidate_idx in remaining_indices:
min_distance = float('inf')
for selected_idx in selected_indices:
distance = np.linalg.norm(X[candidate_idx] - X[selected_idx])
min_distance = min(min_distance, distance)
if min_distance > max_min_distance:
max_min_distance = min_distance
best_idx = candidate_idx
if best_idx is not None:
selected_indices.append(best_idx)
remaining_indices.remove(best_idx)
selected_samples = []
for idx in selected_indices:
selected_samples.append({
'index': idx,
'text': self.unlabeled_data[idx]['text']
})
return selected_samples
def auto_annotate(self, confidence_threshold=0.9):
"""自动标注高置信度样本"""
if not self.unlabeled_data:
return []
texts = [item['text'] for item in self.unlabeled_data]
X = self.vectorizer.transform(texts)
probabilities = self.model.predict_proba(X)
predictions = self.model.predict(X)
auto_annotated = []
indices_to_remove = []
for i, (prob, pred) in enumerate(zip(probabilities, predictions)):
max_confidence = np.max(prob)
if max_confidence >= confidence_threshold:
auto_annotated.append({
'text': texts[i],
'label': pred,
'confidence': max_confidence
})
indices_to_remove.append(i)
# 移除自动标注的样本
for idx in sorted(indices_to_remove, reverse=True):
self.unlabeled_data.pop(idx)
return auto_annotated
# 使用示例
# 初始化主动学习系统
al_system = ActiveLearningAnnotation()
# 添加初始标注数据
initial_texts = ["这个产品很好", "质量太差了", "还可以吧"]
initial_labels = ["positive", "negative", "neutral"]
al_system.add_labeled_data(initial_texts, initial_labels)
# 添加待标注数据
unlabeled_texts = ["非常满意", "不推荐购买", "性价比一般", "超出预期"]
al_system.add_unlabeled_data(unlabeled_texts)
# 训练初始模型
al_system.train_model()
# 获取需要人工标注的样本
uncertain_samples = al_system.uncertainty_sampling(n_samples=2)
diverse_samples = al_system.diversity_sampling(n_samples=2)
print("不确定性采样结果:", uncertain_samples)
print("多样性采样结果:", diverse_samples)
# 自动标注高置信度样本
auto_labeled = al_system.auto_annotate(confidence_threshold=0.8)
print("自动标注结果:", auto_labeled)
🎯 特定领域标注
医学图像标注
import cv2
import numpy as np
from sklearn.cluster import KMeans
class MedicalImageAnnotation:
def __init__(self):
self.annotations = {}
def segment_lesion(self, image_path, roi_coordinates=None):
"""病灶分割标注"""
image = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)
if roi_coordinates:
# 提取感兴趣区域
x1, y1, x2, y2 = roi_coordinates
roi = image[y1:y2, x1:x2]
else:
roi = image
# 使用K-means进行初步分割
data = roi.reshape((-1, 1))
kmeans = KMeans(n_clusters=3, random_state=42)
labels = kmeans.fit_predict(data)
# 重塑为图像形状
segmented = labels.reshape(roi.shape)
return segmented, roi
def annotate_anatomical_structure(self, image_path, structure_type):
"""解剖结构标注"""
structures = {
'heart': {'color': (255, 0, 0), 'thickness': 2},
'lung': {'color': (0, 255, 0), 'thickness': 2},
'liver': {'color': (0, 0, 255), 'thickness': 2},
'kidney': {'color': (255, 255, 0), 'thickness': 2}
}
annotation = {
'image_path': image_path,
'structure_type': structure_type,
'properties': structures.get(structure_type, {'color': (255, 255, 255), 'thickness': 1}),
'timestamp': datetime.now().isoformat()
}
return annotation
def measure_distance(self, point1, point2, pixel_spacing):
"""测量距离(毫米)"""
pixel_distance = np.sqrt((point1[0] - point2[0])**2 + (point1[1] - point2[1])**2)
real_distance = pixel_distance * pixel_spacing
return real_distance
def calculate_area(self, contour, pixel_spacing):
"""计算面积(平方毫米)"""
pixel_area = cv2.contourArea(contour)
real_area = pixel_area * (pixel_spacing ** 2)
return real_area
# 法律文档标注
class LegalDocumentAnnotation:
def __init__(self):
self.legal_entities = [
'PERSON', 'ORGANIZATION', 'LOCATION', 'DATE', 'MONEY',
'LAW', 'CASE', 'COURT', 'JUDGE', 'LAWYER'
]
def extract_legal_entities(self, text):
"""提取法律实体"""
# 这里可以集成专门的法律NLP模型
entities = []
# 简单的规则基础实体识别示例
import re
# 日期模式
date_pattern = r'\d{4}年\d{1,2}月\d{1,2}日'
dates = re.finditer(date_pattern, text)
for match in dates:
entities.append({
'text': match.group(),
'type': 'DATE',
'start': match.start(),
'end': match.end()
})
# 金额模式
money_pattern = r'\d+(?:,\d{3})*(?:\.\d{2})?元'
money_matches = re.finditer(money_pattern, text)
for match in money_matches:
entities.append({
'text': match.group(),
'type': 'MONEY',
'start': match.start(),
'end': match.end()
})
return entities
def annotate_clause_type(self, clause_text):
"""标注条款类型"""
clause_types = {
'权利义务': ['权利', '义务', '责任', '权限'],
'违约责任': ['违约', '赔偿', '损失', '责任'],
'争议解决': ['争议', '仲裁', '诉讼', '管辖'],
'生效条件': ['生效', '终止', '期限', '条件']
}
scores = {}
for clause_type, keywords in clause_types.items():
score = sum(1 for keyword in keywords if keyword in clause_text)
scores[clause_type] = score
# 返回得分最高的条款类型
best_type = max(scores, key=scores.get)
return best_type if scores[best_type] > 0 else '其他'
📈 标注效率优化
批量标注策略
class BatchAnnotationStrategy:
def __init__(self):
self.batch_size = 50
self.strategies = ['random', 'similar', 'diverse', 'uncertain']
def create_batches(self, data, strategy='similar'):
"""创建标注批次"""
if strategy == 'random':
return self._random_batches(data)
elif strategy == 'similar':
return self._similar_batches(data)
elif strategy == 'diverse':
return self._diverse_batches(data)
elif strategy == 'uncertain':
return self._uncertain_batches(data)
def _similar_batches(self, data):
"""创建相似样本批次"""
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
# 假设data是文本列表
vectorizer = TfidfVectorizer(max_features=100)
features = vectorizer.fit_transform(data)
# 聚类
n_clusters = len(data) // self.batch_size
kmeans = KMeans(n_clusters=n_clusters, random_state=42)
clusters = kmeans.fit_predict(features)
# 按聚类分组
batches = {}
for i, cluster_id in enumerate(clusters):
if cluster_id not in batches:
batches[cluster_id] = []
batches[cluster_id].append(data[i])
return list(batches.values())
def estimate_annotation_time(self, batch, complexity_factor=1.0):
"""估计标注时间"""
base_time_per_sample = 30 # 秒
estimated_time = len(batch) * base_time_per_sample * complexity_factor
return estimated_time
def optimize_annotator_assignment(self, batches, annotators):
"""优化标注者分配"""
assignments = {}
for i, batch in enumerate(batches):
# 简单的轮询分配
annotator = annotators[i % len(annotators)]
if annotator not in assignments:
assignments[annotator] = []
assignments[annotator].append({
'batch_id': i,
'batch': batch,
'estimated_time': self.estimate_annotation_time(batch)
})
return assignments
📚 最佳实践
标注指南制定
- 明确标注标准:详细定义每个标签的含义和适用范围
- 提供示例:为每种情况提供正面和负面示例
- 处理边界情况:明确模糊情况的处理方式
- 建立审核流程:设置多级审核和质量控制机制
标注者培训
- 理论培训:介绍项目背景和标注目标
- 实践训练:通过示例数据进行练习
- 一致性测试:评估标注者间的一致性
- 持续反馈:定期检查和改进标注质量
技术工具集成
- 版本控制:使用Git等工具管理标注数据版本
- 自动化检查:开发脚本自动检测标注错误
- 数据备份:定期备份标注数据防止丢失
- 进度跟踪:实时监控标注进度和质量指标
🔖总结
数据标注是连接原始数据与机器学习模型的桥梁,其质量和效率直接影响模型的性能。随着技术的发展,数据标注方法也在不断创新,从传统的人工标注到利用人工智能技术的自动标注,降低了成本,提高了精度。
- 未监督学习和自监督学习为减少标注依赖提供了新的思路,通过挖掘数据内在的结构和信息,训练出具有强大泛化能力的模型。
- 丰富的标注类型满足了不同应用场景的需求,从简单的类别标注到复杂的场景流和占用地图,为模型提供了多层次的语义信息。
- 多样化的标注方法结合了人类智能和机器智能,主动学习、众包标注、合成数据等方法,使得数据标注更加高效和经济。
在未来的发展中,数据标注将继续朝着自动化、智能化、高质量的方向迈进,为人工智能的应用提供更坚实的基础。