数据生成和场景编辑
模块目标:聚焦自动驾驶(Autonomous Driving)场景,系统掌握数据生成方法:传统方法生成及基于生成式模型的方法。
数据生成概述(自动驾驶)
自动驾驶合成数据通过仿真、程序化、或生成式模型构造道路交通场景与多传感器数据(相机、LiDAR、Radar、IMU、GNSS)。其核心价值:
- 覆盖长尾与危险场景(急刹、鬼探头、雨雾夜、逆光、眩光、强遮挡)
- 降低采集与标注成本,同时保证严格的传感器同步与外参一致性
方法总览
知识驱动与基于规则系统(Rule-Based Approaches)
规则/程序生成(Rule-based / Procedural / Agent-based)
做法:人工写规则、文法、程序或代理行为(IF…THEN…、Agent-based 模型)。
优点:可控、可解释、容易加入业务约束/物理规则。
典型场景:仿真器(交通/物流/金融市场)、地形/地图/网络拓扑程序化生成、合成日志。
例如,组合测试用于高效地生成测试用例,通过确保输入参数的关键组合被覆盖来发现系统缺陷。其核心概念是覆盖阵列(Covering Array, CA)。覆盖阵列定义公式 (Covering Array Notation): \(\text{CA}(N; t, k, v)\)
$N$: 数组中的行数(即生成的测试用例总数)。
$t$: 强度(Strength),表示希望覆盖的参数组合的最大元数(例如, $t=2$ 表示覆盖所有两两组合)。
$k$: 参数数量(Number of factors)。
$v$: 每个参数的符号或值数量(Number of symbols per factor)。
一个 $CA(N; t, k, v)$ 是一个 $N \times k$ 矩阵,它使用来自 $v$ 元字母表 $G$ 的符号,确保在任何 $t \times N$ 子数组中, $G^t$ 中的每个 $t$ 元组都被覆盖至少一次。
合成渲染/程序化内容(CGI / Synthetic Rendering)
做法:用 3D 引擎或渲染管线 + 程序化资产/材质/光照/噪声来出图/出视频/出点云,标签自动生成。
优点:可控性强、覆盖极端角落;与仿真/规则法常组合。
经典统计建模与概率推断(Statistical Modelling)
参数化统计建模(Parametric)
核心:假设分布族,估计参数后按分布采样;
优点:高效、抽样简单、易解释;
典型场景:金融风控(联合违约/收益)、可靠性寿命分布、计数/到达过程。
例如:高斯混合模型(GMM)
GMM 假设数据分布是 $K$ 个高斯分量的加权混合 。GMM 的概率密度函数 $p(\mathbf{x})$: \(p(\mathbf{x}) = \sum_{k=1}^{K} \pi_k \mathcal{N}(\mathbf{x}|\mathbf{\mu}_k, \mathbf{\Sigma}_k)\)
-
$\pi_k$: 第 $k$ 个分量的混合权重(先验概率),$\sum_{k=1}^{K} \pi_k = 1$。
-
$\mathcal{N}(\mathbf{x} \mathbf{\mu}_k, \mathbf{\Sigma}_k)$: 第 $k$ 个高斯分布,由其均值 $\mathbf{\mu}_k$ 和协方差 $\mathbf{\Sigma}_k$ 定义。
新数据(样本)的生成过程GMM 的生成是一个分层的随机采样过程
-
参数估计:使用 EM 算法等方法拟合真实数据,获得最优参数 $\Theta = {\pi_k, \mathbf{\mu}_k, \mathbf{\Sigma}_k}$。
-
分层采样:
-
步骤 1 (分量选择):根据混合权重 $\pi_k$ 的离散概率分布,随机选择一个分量 $k$ ;
-
步骤 2 (数据采样):从选定的高斯分布 $\mathcal{N}(\mathbf{x} \mathbf{\mu}_k, \mathbf{\Sigma}_k)$ 中,随机抽取生成新的数据点 $\mathbf{x}$。
-
具体例子:多模态驾驶行为建模用于生成合成驾驶行为数据,其中不同的驾驶模式(如匀速巡航、激进变道)被建模为不同的 GMM 分量 。通过从这些已识别的分布中随机采样,生成具有特定驾驶风格的轨迹数据。
非参数与重采样(Nonparametric / Resampling)
非参数模型对数据的基础分布形式不做强假设,模型复杂度随着数据量增长而变化。重采样技术则通过对现有数据进行重复抽样或分层抽样来创建新的数据样本或估计统计量。
例如:核密度估计(Kernel Density Estimation, KDE)
KDE 是一种非参数密度估计方法,通过对每个数据点放置一个“核函数”(例如高斯核),然后将这些核函数求和来估计整体的概率密度函数。
KDE 估计器 $\hat{f}(x; h)$:\(\hat{f}(x;h) = \frac{1}{n h} \sum_{i=1}^n K \left( \frac{x-X_i}{h} \right)\)
-
$n$: 样本大小。
-
$K(\cdot)$: 核函数(Kernel function),通常是标准正态密度 $\phi(x)$。
-
$h$: 带宽(Bandwidth),控制平滑程度。
KDE 用于非参数密度采样:
-
密度估计:在真实数据集 $X_1, \dots, X_n$ 上拟合 KDE,获得平滑的密度估计 $\hat{f}(x; h)$。
-
生成:从这个估计的密度函数 $\hat{f}(x; h)$ 中随机抽取新的样本点。这相当于首先以 $\frac{1}{n}$ 的概率随机选择一个训练数据点 $X_i$,然后从以 $X_i$ 为均值、带宽 $h$ 为标准差的核分布中抽取一个样本。
具体例子:非对称风险分布生成用于生成具有复杂、非对称分布特征的风险数据(例如,保险索赔金额)。KDE 可以精确地捕捉到传统高斯模型难以描述的偏态和重尾分布,从而生成更具真实统计特征的合成数据。
蒙特卡洛方法(Monte Carlo Method, MC)
MC 是一种基于独立重复随机采样的计算技术,通过从预定义分布中抽取大量样本来近似结果 。
MC 可用于通过大量随机样本对期望值 $\mathbb{E}[f(X)]$ 进行近似 :
\[\mathbb{E}[f(X)] \approx \frac{1}{N} \sum_{i=1}^{N} f(x_i)\]-
$N$: 样本数量。
-
$x_i$: 从预定义的概率分布 $P(X)$ 中抽取的随机样本。
MC方法通过随机化不确定性输入来创建合成情景。
-
定义模型与变量:明确模拟模型 $f(X)$,并确定输入变量 $X = {X_1, X_2, \dots}$。
-
指定概率分布:为每个输入变量 $X_i$ 指定概率分布(例如, $\mathcal{N}$)及其参数。
-
重复采样:从这些指定的输入分布中独立随机抽取 $N$ 组输入样本。
-
运行模拟:将每组输入样本代入模型 $f(X)$ 中运行,生成 $N$ 个合成结果 $f(x_i)$。
概率图模型 / 隐变量模型(PGM / Latent-variable)
核心:用图结构刻画条件独立,定义生成过程并据此采样。
做法:贝叶斯网络、马尔可夫网络、HMM/HSMM、LDA、混合成员模型;
优点:结构化可解释;能编码先验与因果/条件独立关系。
贝叶斯网络(Bayesian Networks)
贝叶斯网络是一种有向无环图(DAG),用于表示变量间的条件依赖关系。
贝叶斯网络定义了所有变量的联合概率分布,它是每个节点基于其父节点的条件概率的乘积:
\[P(X_1, X_2, \dots, X_n) = \prod_{i=1}^n P(X_i | \text{Parents}(X_i))\]$\text{Parents}(X_i)$: 节点 $X_i$ 在图中的父节点集合。
贝叶斯网络通过前向采样(Ancestral Sampling)生成新数据,这是一种基于其图结构的有向采样过程。
-
拓扑排序:确定节点的依赖顺序(即从根节点开始)。
-
前向采样:按照拓扑顺序,从每个节点的条件概率分布(CPD)中抽取样本。首先从没有父节点的根节点开始抽取,然后抽取依赖于这些节点的子节点,直到所有变量都获得一个值。
具体例子:交通事故因果分析数据生成用于生成具有复杂因果依赖关系(如“天气”影响“路况”,“路况”和“驾驶行为”共同影响“事故率”)的交通事故数据。通过前向采样,可以生成保证因果关系一致的合成场景数据。
Generative model
辅助技术:潜在空间插值(Latent Space Interpolation)
潜在空间插值是一种数据生成技术,它本身不是独立的模型,而是 VAE 等深度生成模型用于数据增强和探索潜在空间的关键技术 。
数学公式最常用的线性插值形式: \(\mathbf{z}_{\text{interp}} = \alpha \mathbf{z}_A + (1 - \alpha) \mathbf{z}_B\)
$\mathbf{z}_{\text{interp}}$: 插值后的潜在向量。
$\mathbf{z}_A, \mathbf{z}_B$: 两个来自潜在空间的起始向量。
$\alpha$: 插值系数,其中 $\alpha \in [0,1] $。
新数据(平滑变体)的生成过程该技术利用深度模型(尤其是 VAE)潜在空间的连续性来构造新数据 。
选择锚点:在已训练模型的潜在空间中,选择两个代表不同特征的潜在向量 $\mathbf{z}_A$ 和 $\mathbf{z}_B$。
构造路径:根据插值公式,在 $\mathbf{z}A$ 和 $\mathbf{z}_B$ 之间生成一系列中间向量 $\mathbf{z}{\text{interp}}$。
解码:将每个 $\mathbf{z}_{\text{interp}}$ 输入到生成器网络(解码器)中。
输出:生成器输出一个连续的、从 $\mathbf{x}_A$ 渐变到 $\mathbf{x}_B$ 的新合成数据序列。
具体例子:
-
驾驶轨迹的细微变异生成用于生成 ADS 验证所需的边缘案例。通过插值,可以平滑地生成从“安全跟车”轨迹到“轻微追尾风险”轨迹之间的一系列细微变异数据,用于评估 ADS 对不确定性的鲁棒性。
-
人脸转换,从一张人脸转换到另一张人脸。如图1(StyleGAN2)所示。

常见生成模型比较
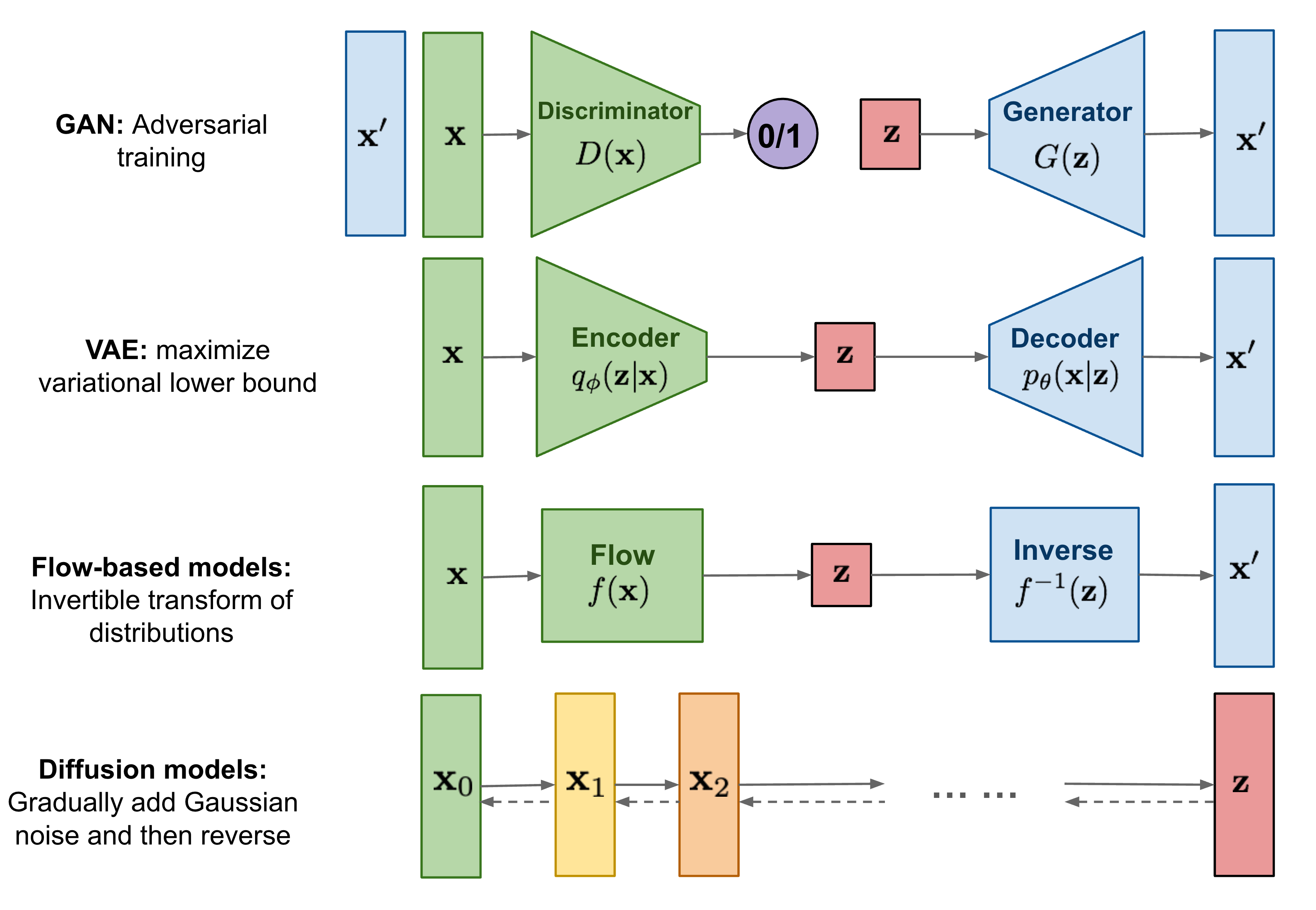
如图 2所示。
Variational AutoEncoders (VAE)
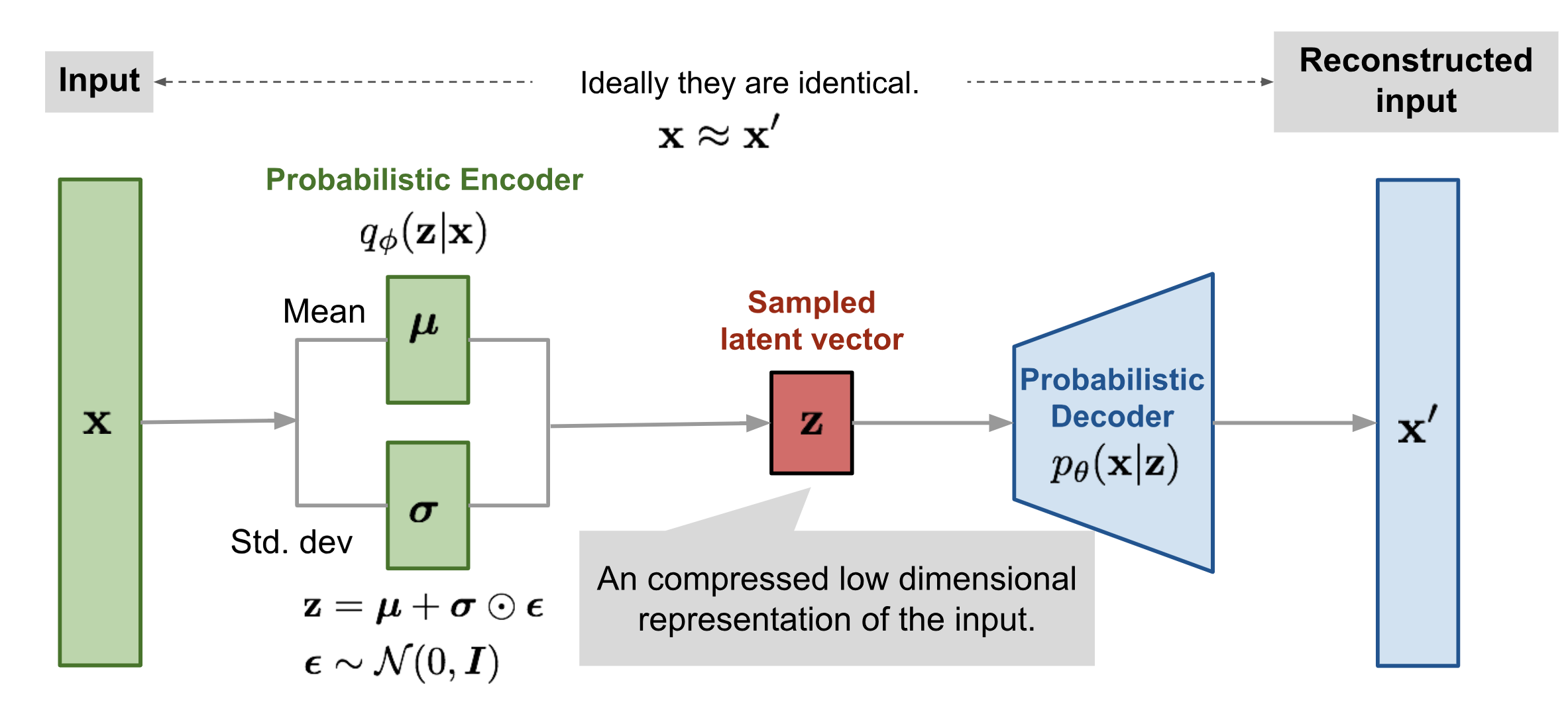
如图 3所示,VAE 将输入数据 $\mathbf{x}$ 编码为潜在空间 $\mathbf{Z}$ 上的一个概率分布 $q_{\phi}(\mathbf{z})$核心公式 (Core Formula)证据下界 (ELBO) 的最大化 (Maximization of the Evidence Lower Bound)。
VAE 通过最大化 ELBO 来近似数据的对数似然 $\log p(\mathbf{x})$ :
\[\mathcal{L}(\theta,\phi;\mathbf{x}) = \mathbb{E}_{\mathbf{z}\sim q_\phi(\mathbf{z}\mid \mathbf{x})} \!\left[\log p_\theta(\mathbf{x}\mid \mathbf{z})\right] - \mathrm{KL}\!\left(q_\phi(\mathbf{z}\mid \mathbf{x})\,\|\,p(\mathbf{z})\right).\]损失函数 (Loss Function)最大化 ELBO(即最小化负 ELBO)。
损失函数平衡了两个目标:
-
重建损失 (Reconstruction Loss):$\log p_{\theta}(\mathbf{x})$
-
KL 散度损失 (KL Divergence Loss):$D_{KL}$ 项,作为正则化,强制学到的潜在分布 $q_{\phi}$ 接近先验分布 $p(\mathbf{z})$。
GAN
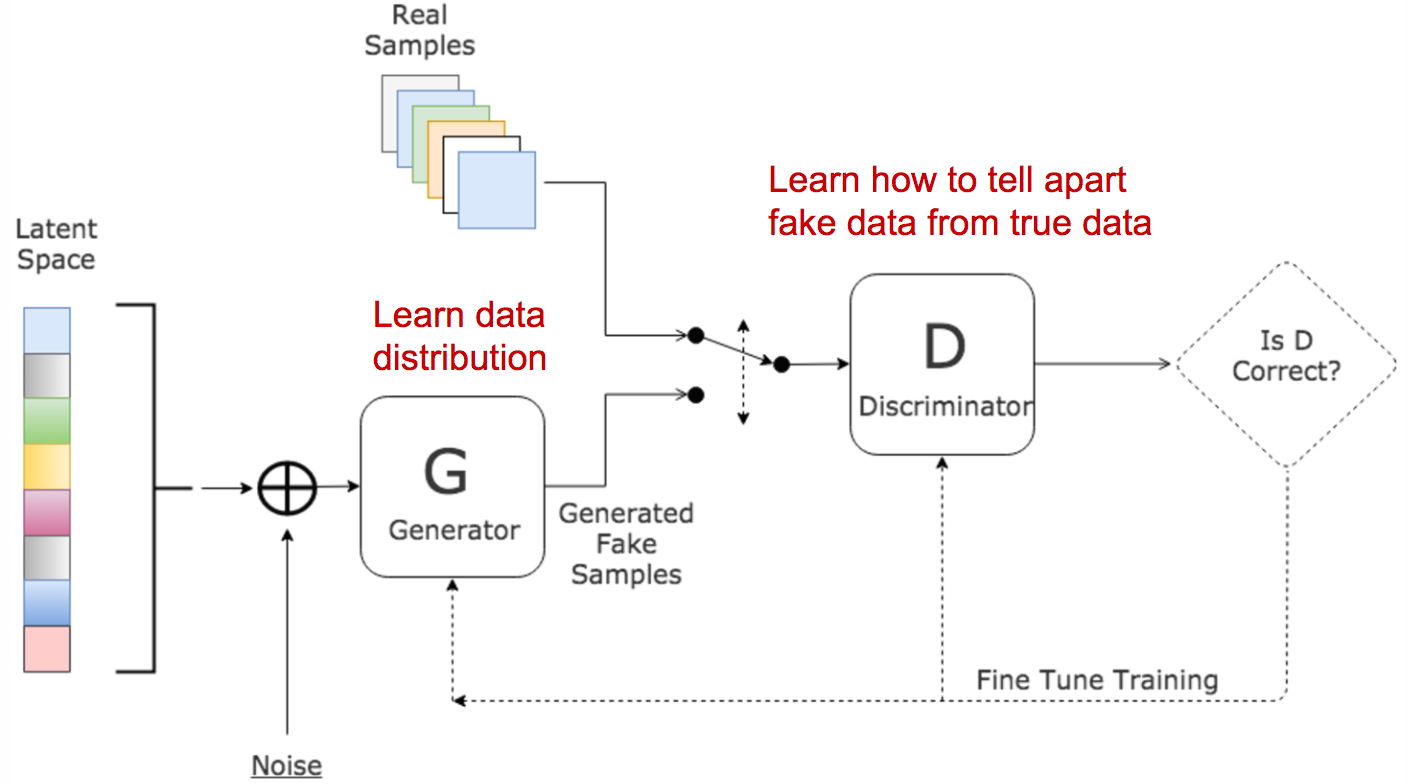
如图 4所示,GAN 由两个相互竞争的网络组成:生成器 ($G$) 负责生成逼真样本,判别器 ($D$) 负责判断样本是真实 ($x$) 还是伪造 ($G(z)$)。
\[\min_{G} \max_{D} V(D, G) = \mathbb{E}_{\mathbf{x} \sim p_{data}(\mathbf{x})} + \mathbb{E}_{\mathbf{z} \sim p(\mathbf{z})}\]损失函数 (Loss Function):对抗性损失(零和博弈)。
-
判别器 ($D$) 目标:最大化 $V(D, G)$。它希望对真实样本 $x$ 的判断 $D(x)$ 接近 1,对生成样本 $G(z)$ 的判断 $D(G(z))$ 接近 0。
-
生成器 ($G$) 目标:最小化 $V(D, G)$。它希望 $D(G(z))$ 接近 1(即成功欺骗 $D$)。
Normalizing Flow
如图 5所示
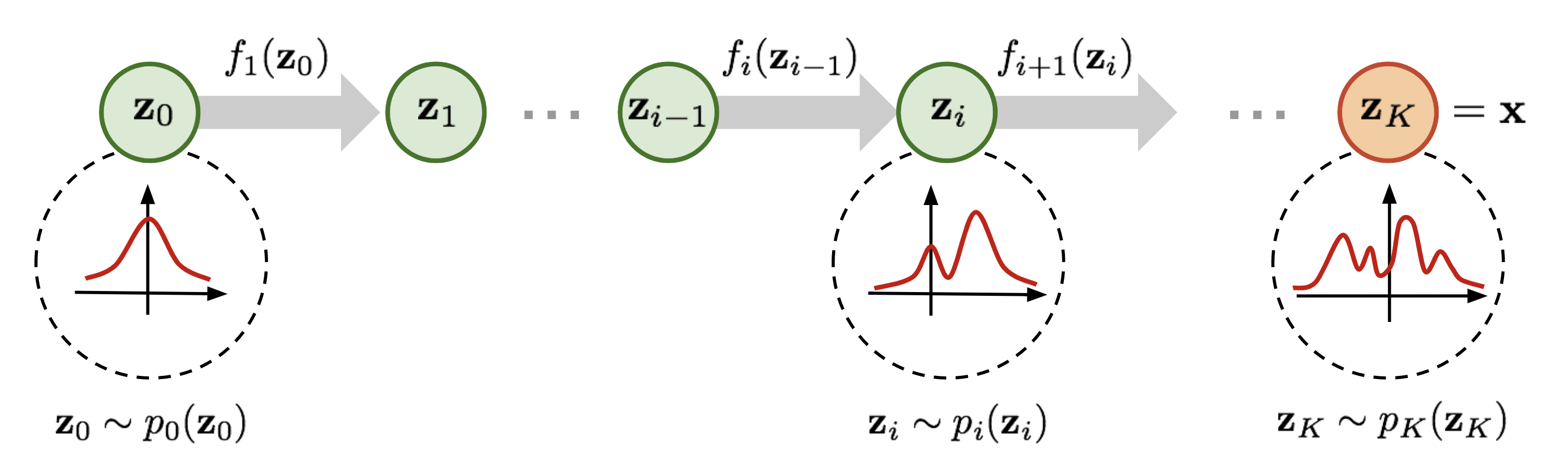
- Exact likelihood via change of variables (computable and differentiable):
Diffusion
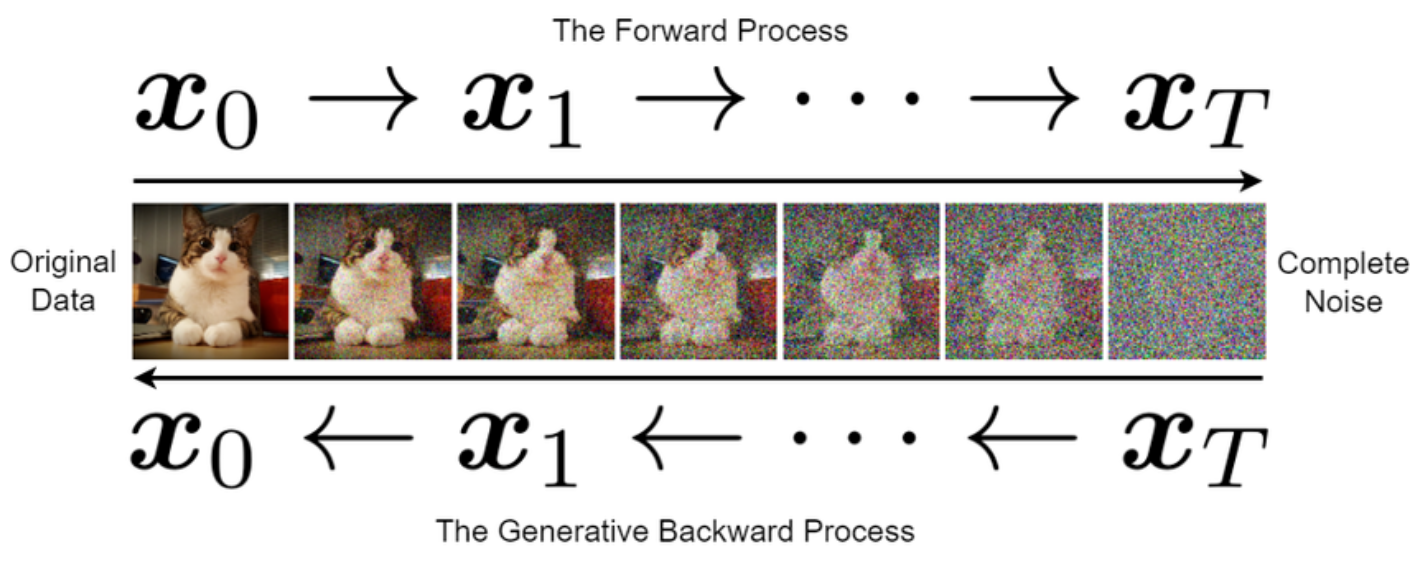
如图 6所示,Diffusion模型有前向和反向的过程:
-
前向过程逐步加噪声至纯噪声$\mathbf{x}_T$。
-
反向过程训练一个神经网络 $\epsilon_{\theta}$ 预测并去除噪声,将 $\mathbf{x}_T$ 逐步恢复到数据 $\mathbf{x}_0$。
DM 的训练目标是学习一个模型 $\epsilon_{\theta}$ 来预测在任意时间步 $t$ 时加入的噪声 $\epsilon$:
\[\mathcal{L}_{\text{simple}} = \mathbb{E}_{t,\mathbf{x}_0,\boldsymbol{\epsilon}}\Big[\,\big\|\boldsymbol{\epsilon} - \boldsymbol{\epsilon}_\theta(\mathbf{x}_t,t)\big\|_2^2\,\Big],\\ \mathbf{x}_t = \sqrt{\bar{\alpha}_t}\,\mathbf{x}_0 + \sqrt{1-\bar{\alpha}_t}\,\boldsymbol{\epsilon},\; \boldsymbol{\epsilon}\sim\mathcal{N}(0,I)\]损失函数均方误差 (MSE) 损失。
目标:最小化预测噪声 $\epsilon_{\theta}$ 与真实噪声 $\epsilon$ 之间的 L2 距离。这一基于似然的稳定目标确保了训练的稳定性和优异的生成质量。